Blog
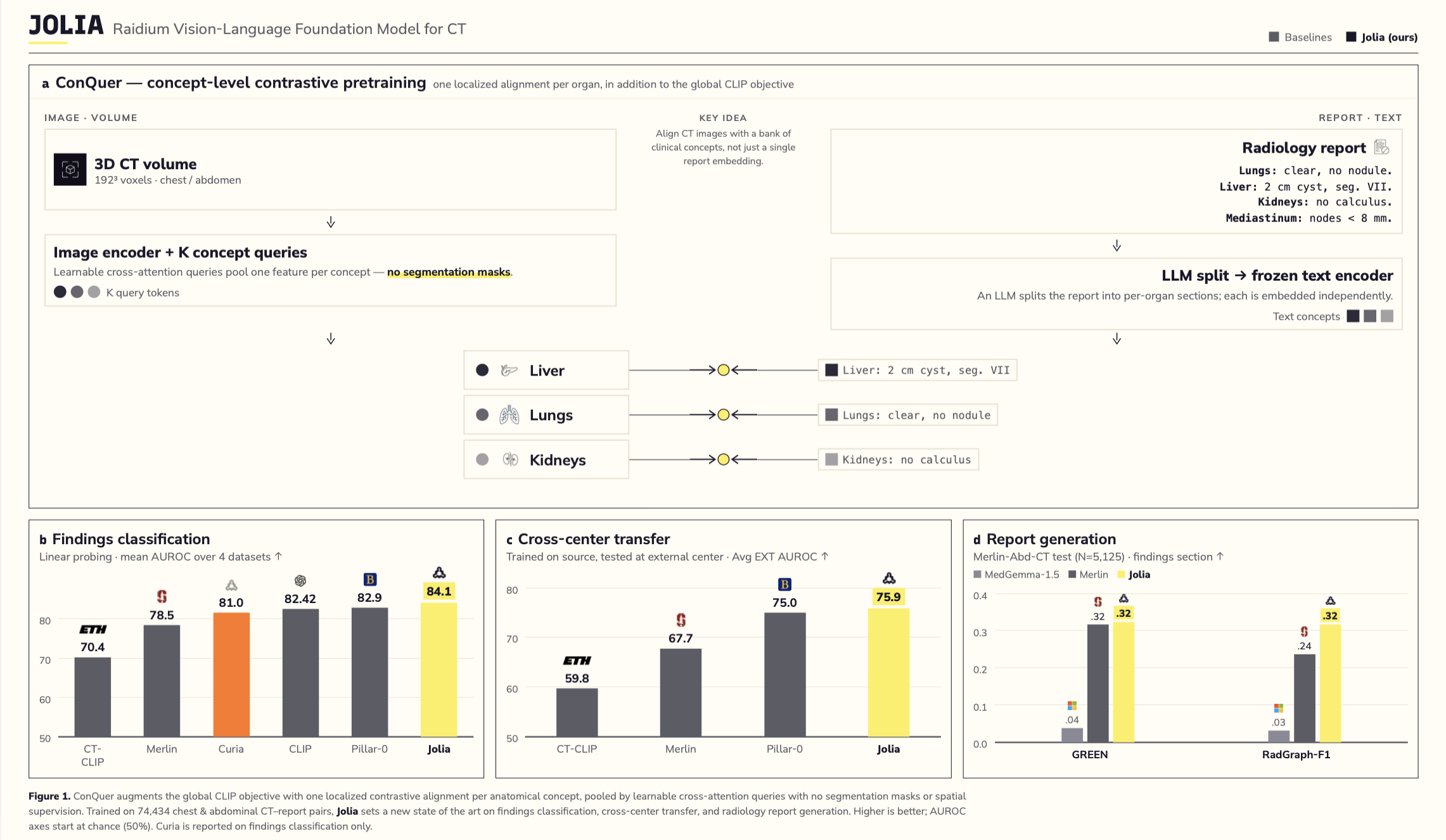
Introducing Jolia: Our Vision-Language Foundation Model for CT
June 24, 2026
At Raidium, building toward AGI in radiology requires models that do more than see. They need to understand — to read a scan the way a radiologist doe...
One Model, Any Task: Why Foundation Models Are Changing Radiology Workflows
May 27, 2026
For years, the conversation around AI in radiology has moved fast. New tools, new benchmarks, new promises. However, despite all of this activity, man...
Introducing RadImageNet-VQA: A New Benchmark for Radiologic Visual Understanding
April 22, 2026
Interpreting radiology exams requires combining visual recognition and clinical reasoning, often with medical context. To be useful in this setting, a...

ECR 2026: What the "Rays of Knowledge" Revealed About the Future of Imaging
April 2, 2026
ECR 2026 chose its theme well. "Rays of Knowledge" captured a moment of clarity about where the field stands right now. The conversation has moved onAt RSNA 2025, we wrote about the shift from narrow point solutions to comprehensive AI workflows. ECR 2026 confirmed that this shift is no longer a prediction, but a reality.The question at ECR was no longer "does AI work?" It was: who controls the diagnostic journey, and how do we build tools that radiologists will actually trust and use?The answer, heard across booth conversations, plenary sessions, and AI theater panels, was consistent: fragmented tools are losing traction. Radiologists are actively moving beyond narrow AI solutions. Single-feature tools are being replaced by multi-modal, workflow-integrated platforms. Therefore, the next competitive advantage in machine learning research for radiology belongs to those who control the workflow, not just a single task within it.The clinical priorities that defined the weekTwo themes stood out.The first was the automation of the longitudinal follow-up of tumors and the advent of total tumor burden as biomarker. While many research groups across the world are working on this problem, the oncology workload remains high for radiologists, and current AI models face reliability issues preventing clinical use. Innovative solutions are required to streamline the oncology workflow for a more comprehensive and reproducible assessment of tumor burden, especially with the recent advances on liquid biopsies.The second was the rise of orchestrated AI workflows, systems that reason across an entire case, not just a single image. More specifically, multimodal language models are the missing layer to make AI a genuine assistant to the radiologist, not just a detection engine that produces one more finding to review. AI tools are increasingly being evaluated on economic and workflow impact, not just diagnostic accuracy. The metrics that institutions now care about include time saved per exam, disagreement rate with the radiologist, and institutional adoption rates over time. The question is no longer whether AI can detect, it's whether it can fit seamlessly into the workflow and prove its value at scale.What this means for the next frontier of oncology imagingThe radiologist's role is at an inflection point. Specialties like neurology and oncology are moving into AI-enabled workflows that were historically the domain of radiology. If radiologists do not own the tools in their own workflow, other specialties will, and in stroke detection and fracture identification, this is already happening. Reclaiming that position requires more than a better algorithm. It requires a unified platform that manages the full diagnostic journey, from detection to segmentation to longitudinal tracking, while keeping the radiologist in the loop at every step that matter… One where technical complexity is managed invisibly, and the physician can focus on the patient behind the pixel. UX is not a secondary concern, as a single unnecessary click is enough for a radiologist to abandon a tool, which is why workflow fit is a clinical adoption prerequisite, not a product refinement.ECR 2026 confirmed our directionThe work ahead is to translate foundation model capabilities into a unified radiology workflow that earns trust, one case, one institution, one clinical team at a time.For more updates as we continue to push the boundaries of AI in precision radiology:[SUBSCRIBE_BUTTON]

Introducing Curia-2: Scaling the Next Frontier of Radiology
March 5, 2026
Foundation Model Evaluation at a Glance Curia-2 sets a new standard for general-purpose radiological AI. By managing technical complexity through logic-driven innovation, Curia-2 outperforms leading foundation models from industry and academia across 2D, 3D, and clinical finding tracks.Curia-2 implements an optimized training strategy building upon the original Curia frameworkCuria-2 sets a new state of the art, outperforming competing vision-language models (VLMs) from industry leaders on 2D tasksCuria-2 achieves the highest accuracy across vision-only models, establishing a new benchmark for 3D-first oncology workflows.Curia-2 effectively compares with specialized VLMs on complex finding detection tasks.I. The Shift from Narrow AI to Technical FrameworksWe are entering a new era of diagnostic logic. While traditional AI has relied on narrow, task-specific architectures for every modality or disease, this approach lacks the scalability required for modern medicine. Today, we are moving beyond these boundaries, whether in oncology, neurology, or musculoskeletal health, to introduce Curia-2.Building upon the Curia framework, which demonstrated the power of scale by pre-training on over 200 million CT and MRI slices, Curia-2 significantly improves upon the original strategy to better capture the specificities of radiological data. Curia-2 is a broad foundation model designed as a shared technical framework. By training on vast, unlabeled datasets, it moves beyond simple observation to a deep understanding of structural characteristics and tissue frameworks. This transition from "narrow tools" to "general-purpose frameworks" represents the critical breakthrough needed to reach the next frontier of health: AGI for radiology. This progress is dedicated to modernizing oncology workflows and ensuring that technical complexity is managed so that clinicians can remain patient-centered.II. Results: Setting a New StandardEvolving the Foundation: Scaling Technical Frameworks with Curia-2Curia-2 represents an evolution of our original framework, moving beyond simple scale to a more refined understanding of structural characteristics. Unlike the initial Curia models, Curia-2 demonstrates a clear, consistent scaling benefit as we move from Base to Large architectures.2D Track Advancement: Curia-2 L (88.5%) and Curia-2 B (86.8%) consistently outperform the original Curia L (87.9%) and Curia B (86.2%).3D Track Advancement: The advancement is even more pronounced in 3D-first workflows, where Curia-2 L achieves 88.6% accuracy compared to 83.4% for Curia L, a significant increase in managing technical complexity across volumes.Figure 3. 3D Track comparison of Curia-2 to Curia-1Benchmarking Against the Frontier: Industry & Academic LeadersTo measure Curia-2's impact, we benchmarked it against newly released models from industry leaders and top academic institutions. Curia-2 achieves these milestones with increased data efficiency, reaching higher performance much earlier in the training process.2D Track Performance: As shown in our latest evaluations, Curia-2 L achieves an average performance of 88.5%. This significantly exceeds competing 2D VLMs such as Microsoft’s MedImageInsight (84.4%), Google’s MedGemma (80.1%), and Microsoft’s BioMedCLIP (79.1%).Figure 4: 2D Track Results. Curia-2 demonstrates higher precision in structural understanding compared to leading 2D foundation models.3D Track Competitive Edge: On the 3D track, Curia-2 L reaches an accuracy of 88.6%, setting a new standard for 3D-first oncology workflows. It outperforms the highest-performing visiol-language models such as Microsoft’s MedImageInsight (83.6%) and Google’s MedGemma (81.8%), while remaining significantly ahead of specialized 3D-native architectures like Stanford’s Merlin (65.4%) and ETH Zurich’s CT-CLIP (51.5%).Figure 5: 3D Track results. Curia-2 achieves the highest accuracy, setting a new standard for 3D-first oncology workflows.Addressing Clinical Complexity: Finding DetectionTraditionally, finding detection, identifying around 200 clinical entities, was thought to require the domain-specific knowledge of Vision-Language Models (VLMs). Because models such as BioMedCLIP and MedImageInsight use explicit language supervision, they have a natural advantage in translating pixels into complex clinical findings.However, Curia-2 proves that a pure vision-only technical framework can bridge this gap through superior structural understanding alone. Curia-2B achieves a peak AUC of 80.2%, where Curia-2 L followed closely with a score of 79.7%, both as vision-only models. This performance not only outpaces specialized VLMs like MedImageInsight (79.0%), BioMedCLIP (74.1%), and MedGemma (72.7%) but also remains highly competitive with high-end 3D-native architectures such as Pillar-0 (82.4%) and Merlin (81.2%).Notably, this generational leap highlights the progress made since our initial release; while the original Curia L established a strong baseline at 79.2%, the refined logic of Curia-2 has effectively crossed the performance gap into VLM-level clinical precision for oncology workflows.Figure 6: Competitive Performance on Finding Detection Tasks: Curia-2 (vision-only) competes with specialized VLMs.Optimized Data EfficiencyA key emergent property of Curia-2 is its data efficiency. Curia-2 L demonstrates quicker convergence, requiring significantly fewer training samples to achieve the same performance level as other frontier models. This ensures that technical complexity is managed to provide stable frameworks for diagnostic insights earlier in the development process.Figure 7: Evaluation of Data Efficiency and Model Convergence.III. Logic and Innovation: Evolving from Curia to Curia-2The original Curia model set a new precedent for scale, demonstrating the power of pre-training on over 200 million CT and MRI slices. However, as the field moves toward billion-parameter architectures, managing technical complexity requires a more refined approach to how models learn from 3D volumes. Curia-2 represents a logic-driven evolution of this foundation.Through grounded innovation, we have optimized our training strategy to focus on meaningful tissue frameworks:Efficiency: A multi-stage resolution strategy allows the model to capture high-fidelity structural characteristics with greater stability and optimized computational cost.Context: Technical complexity is managed through content-aware filtering and anatomically-guided sampling, ensuring the model prioritizes informative structural regions over non-informative background.Latent Structure Consistency: We implemented a refined regularization logic that ensures similar structural representations with high consistency across different patients. This framework preserves the nuanced structural characteristics needed for precise clinical differentiation.IV. A Unified Benchmark: 2D, 3D, and Finding DetectionTo ensure a rigorous assessment of these structural advancements, we have reformulated our evaluation strategy. Following the success of CuriaBench, our original 19-task benchmark designed to test clinical versatility, we have restructured this technical framework into two parallel tracks tailored for modern 3D-first oncology workflows.Curia-2 is evaluated across three distinct diagnostic pillars to provide consistent insights necessary for Human-in-the-Loop decision-making:2D Vision: Dedicated to slice-based structural recognition and evaluation of 2D foundation models.3D Vision: A universal volumetric evaluation track providing a standardized benchmark across all anatomical regions.Finding Detection: A specialized track that translates complex volumetric data into clear, actionable insights for nearly 200 distinct clinical entitiesV. Conclusion: Building the Next FrontierCuria-2 marks a pivotal evolution in our mission toward Radiology AGI. By moving beyond the initial scale of Curia and the clinical versatility of CuriaBench, we have optimized our technical framework to master deep structural characteristics. This logic-driven approach enables Curia-2 L to set a new state-of-the-art with 88.5% on 2D tasks and 88.6% on 3D tracks, outperforming frontier models. Now available on Hugging Face, Curia-2 serves as a robust backbone for the global community. This progress brings us closer to our mission: achieving AGI in radiology to empower doctors and allowing them to focus on what matters most—the patient.Ready to explore Curia? Here’s where to start:Download Curia-2B code from HuggingFaceContact us to access Curia-2 L model.Read our preprint on arXivRead our other Curia blogposts:Curia: A Frontier Foundation Model for 3D ImagingAnnouncing the Release of the Curia Benchmark and Evaluation CodeAcknowledgements: Thank you to our partners CIN, IDRIS + GENCI, and Leonardo (CINECA, EuroHPC)

What’s New in AI Radiology After RSNA 2025: AI Re-Inventing Itself, From Point Solutions to the AI-Native Era
December 18, 2025
RSNA 2025, themed “Imaging the Individual,” marked a significant shift in the trajectory of medical imaging. We have moved past the era of narrow AI solutions into a cycle of consolidation and foundational infrastructure. For investors, the message was clear: the future belongs to those who control the workflow and the underlying model.The Rise of the Foundation Model: from Research to RoadmapThe most significant AI trend of the conference was the emergence of Foundation Models—broad-spectrum AI capable of redefining the imaging ecosystem. Multi-modal and vision-language models (VLMs) have officially moved from “interesting research” into enterprise workflow roadmaps.Multi-Modal Entrants: Companies like Meca Health are building models that consume imaging, text, and workflow data to generate next-generation reports from X-ray-based solutions.The Connective Tissue: Actors such as HOPPR and Aidoc are positioning themselves as modality-agnostic platforms, acting as the underlying layer across the hospital.Strategic consolidation: The market signal is loud—Radiology Partners’ Mosaic division recently acquired Cognita to integrate foundation-model capabilities directly into their platform. This confirms that the next competitive battleground is foundational AI embedded in infrastructure, not standalone point solutions.Agentic Workflows: The New Battlefield for ProductivityIf foundation models are the "brain," agentic workflows are the "hands" that finally put that intelligence to work. The industry has moved beyond fragmented point solutions; hospitals are no longer buying features, they are buying order and cohesion.From Interpretation to Orchestration: The goal has shifted from answering a specific clinical question to managing the entire diagnostic journey.The Challenge to Traditionals: Traditional PACS and workstation manufacturers are being challenged by this new layer of intelligence. The "battlefield" is no longer about who has the best viewer, but who controls the agent that routes data, automates segmentation, and generates audit-ready structured outputs.The “Immaturity” Hurdle: As Dr. Paul Chang (University of Chicago) warned during the conference, we must move past the "Four Horsemen of AI Immaturity" toward “useful agents to do useful things”—shifting from autonomous hype to practical orchestration.Raidium: The Intersection of Intelligence and UtilityAt Raidium, we are positioned at the crossroads of these two critical market needs.The model: We have developed a promptable CT/MR foundation model (trained on more than one billion images) designed to be fine-tuned to enterprise workflows—automating segmentation, enabling longitudinal tracking, and standardizing outputs.The interface: Unlike models that remain "invisible" in the background, we provide an Ai-native standalone viewer. By putting our model directly into the radiologist's day-to-day workflow, we ensure immediate adoption and measurable ROI.Significant moves from the Radiology AI ecosystem2B+ USD acquisition of Intelerad by GE: Cloud is where the value is captured todayIntelerad's strategic acquisition by GE Healthcare is a significant signal from the radiology business, where the core value in today's radiology IT and software market is predominantly captured by the Enterprise PACS (Picture Archiving and Communication System). This system serves as the central hub for image storage, access, and distribution, becoming the critical infrastructure for diagnostic efficiency and clinical workflow across an entire healthcare network. This is also a way to allow the scalability of AI deployment.Bayer & Blackford: Is the AI radiology marketplace business declining?Pharmaceutical giant Bayer announced plans to deprioritize its investment in AI platform company Blackford Analysis as part of a general move away from the platform business. Bayer is also winding down its investment in Calantic Digital Solutions, the digital platform company it formed in 2022. This signals that, in the foundation model era, the highest value in radiology is shifting away from third-party marketplaces toward integrated, foundational AI infrastructure.The Return of CapitalWhile ROI remains a discreet conversation, it is the primary driver of current funding and IPO momentum. The industry is looking for scale and lock-in, qualities found only in infrastructure that provides predictable productivity lifts. For strategic leaders and investors, securing a foundation-model partner is now a time-sensitive strategic priority to maintain a technological edge.Want to read more of our radiology events' digest?[SUBSCRIBE_BUTTON]
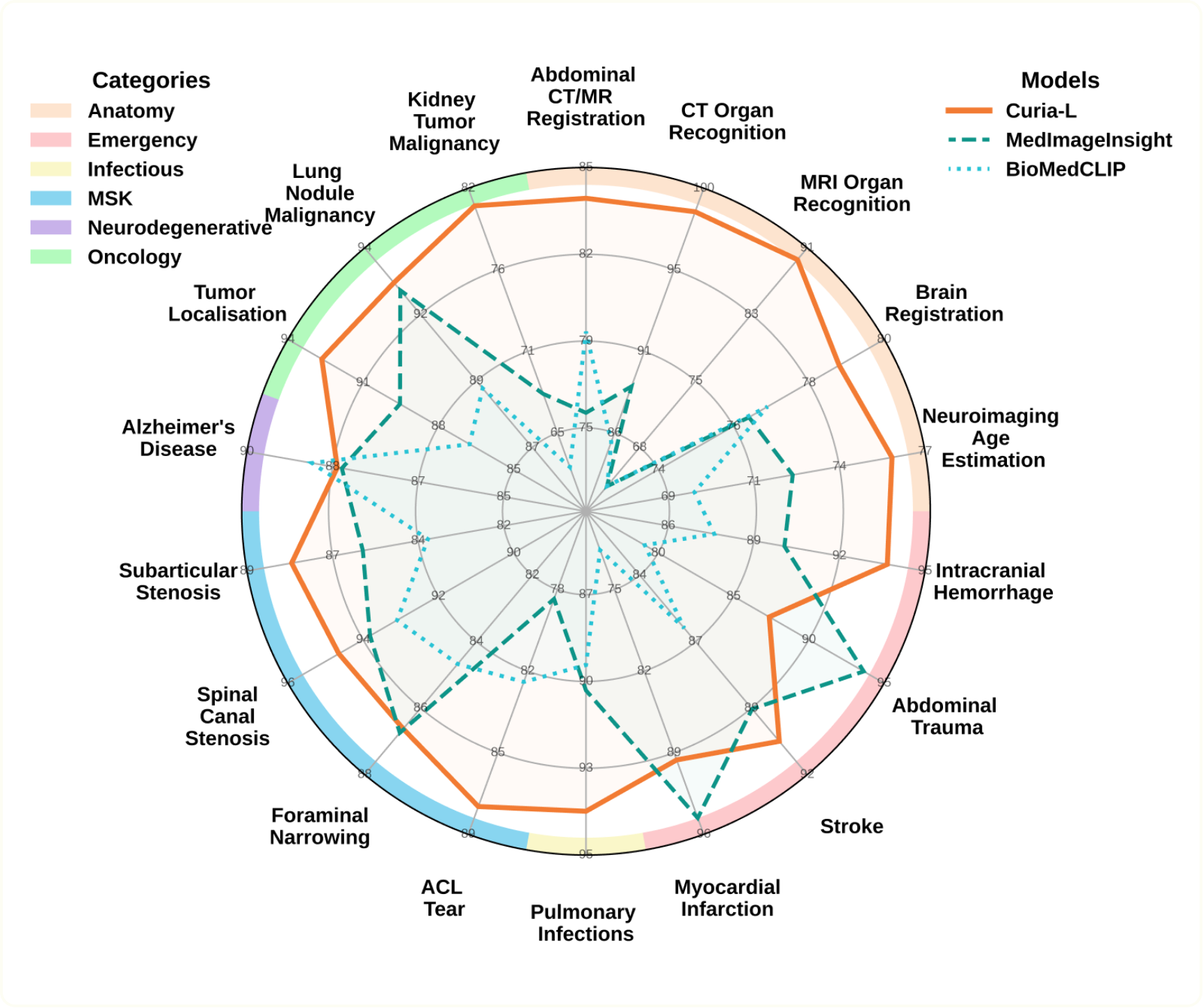
Announcing the Release of the Curia Benchmark and Evaluation Code
October 22, 2025
Following the release of Curia, our multi-modal foundation model for radiology, we are excited to announce the public release of our exclusive 19-task benchmark, named CuriaBench. CuriaBench offers the community a robust tool to compare Curia against various state-of-the-art models. It covers a broad spectrum of clinical cases, representative of the variety of radiologists’ use cases and allows for the exploration of generalization in few-shot and cross-modal settings.CuriaBench: A Benchmark Reflecting the Spectrum of Radiologists’ Clinical CasesCuriaBench comprises 19 distinct radiological tasks that span both CT and MRI modalities covering most anatomical regions. A demo of each of those tasks can be found in the introduction to Curia.The benchmark's tasks fall into several categories:Anatomical Tasks: These evaluate the model's ability to identify organs across various body regions and demonstrate its cross-modality generalization capabilities. Taks include MRI and CT Organ Recognition, Neuroimaging Age Estimation, and Image Registration.Oncology: Focusing on cancer-related challenges, this category includes Lung Nodule and Kidney Lesion Malignancy classification, Tumor Anatomical Site identification, and Kidney Cancer Survival prediction.Musculoskeletal: Tasks here involve assessing degenerative diseases of the lumbar spine, specifically Foraminal Narrowing, Subarticular Stenosis, and Spinal Canal Stenosis, as well as detecting ACL tears from knee MRI.Emergency: This high-stake section evaluates the detection of acute conditions like Intracranial Hemorrhages, Myocardial Infarctions, Abdominal Trauma, and Signs of a Stroke.Infectious: This part of the benchmark focuses on detecting Pulmonary Infections from chest CT scans, including COVID-19 and non-COVID pneumonia.Neurodegenerative: This task involves predicting Alzheimer's disease from brain MRI images.We evaluated Curia's performance against two leading models in the field, including BiomedCLIP and MedImageInsight. Our analysis shows that Curia consistently meets or surpasses the performance of these models and even delivers performance comparable to, or exceeding, that of senior resident radiologists on most benchmark tasks.Releasing the Evaluation Codebase and Trained HeadsTo ensure full reproducibility and accelerate community research, we're releasing the evaluation codebase for CuriaBench. This release is crucial as it enables you to:Reproduce Curia's results from our paper and the benchmark.Test your own data on Curia.Use Curia for a specific downstream task without fine-tuning your own head.We are releasing multiple types of heads, adapted for different problems: linear heads for simple classification tasks, or attention-based heads designed to find more subtle signs of pathologies in images. We are always eager to learn more about how Curia serves the community, so we invite you to share your results with us! Check out the code here: https://github.com/raidium-med/curiaApplying Curia to new tasks: FOMO and UNICORN ChallengesTo further demonstrate Curia’s versatility and generalization capabilities, we recently participated in two challenges hosted around MICCAI 2025: the FOMO and UNICORN challenges.FOMO 2025 (Foundation Model Challenge for Brain MRI): This challenge focused on few-shot generalization and the impact of self-supervised pre-training on downstream performance in the brain MRI domain. The tasks included infarct detection, meningioma segmentation, and brain age estimation. We completed in the open track, allowing us to leverage our foundation model on any combination of data.UNICORN 2025 (Unified beNchmark for Imaging in Computational pathology, Radiology and Natural language): This challenge aimed to establish a comprehensive public benchmark for multimodal foundation models in medical imaging. It used a "one-to-many" approach, assessing how a single model could adapt to a variety of tasks across radiology and pathology. A key takeaway from our participation was demonstrating how rapidly and effectively Curia can be deployed to tackle completely new challenges. We believe the model’s versatility is its greatest strength, and we're highly motivated to see its capabilities further explored. If you are using Curia for novel applications or tasks, we strongly encourage you to connect with our team to share your use cases!Access the Benchmark and MoreDownload the benchmark code from HuggingFaceDownload the evaluation codebase from GitHubRead our preprint on arXivStay tuned for more updates:[SUBSCRIBE_BUTTON]Thank you to all contributors of the datasets we used to develop our benchmark: Wasserthal (TotalSegmentator CT, TotalSegmentator CT &MRI), D'Antonoli (TotalSegmentator MRI), the Brain Development Project (IXI Dataset), Settio (LUNA16), Heller (KiTS23), Yan (DeepLesion), Štajduhar (KneeMRI dataset), MICCAI 2020 challenge (EMIDEC), Liew (ATLAS v2.0), Marcus (OASIS-1), Gunraj (COVIDx CT), Hering (Learn2Reg Challenge), Segars (XCAT Phantom), Ji (AMOS22), Clark (TCGA-KIRC / TCIA), RSNA Challenge, 2024 (RSNA 2024 Lumbar Spine Degenerative Classification), RSNA Challenge, 2023 (RSNA 2023 Abdominal Trauma Detection), RSNA Challenge, 2019 (RSNA ICH Detection)
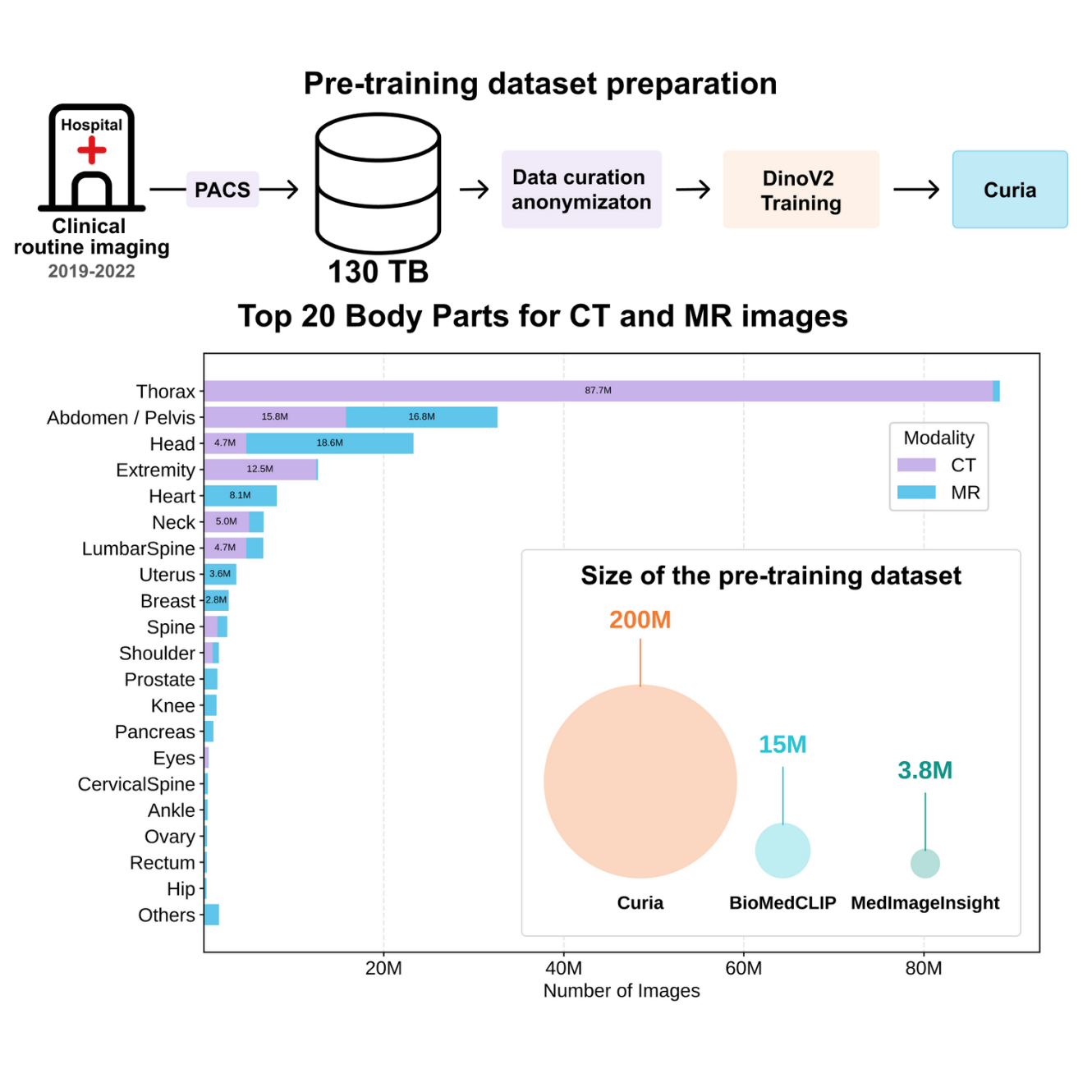
Curia: A Frontier Foundation Model for 3D Imaging, Opening a New Era of AI in Radiology
September 9, 2025
We are thrilled to announce the public release of Curia, a groundbreaking multi-modal foundation model poised to transform radiological image interpretation and accelerate progress in AI for healthcare. Curia is, to our knowledge, the strongest foundation model specifically designed for precision radiology, with a focus on cross-sectional imaging (CT and MRI slices).Radiological image interpretation is fundamental to countless clinical diagnoses, yet the traditional approach of building task-specific AI for every imaging modality, disease, and radiological feature is simply not scalable. Foundation models offer a powerful solution by training on vast, uncurated sets of unlabeled data, learning comprehensive features that can be applied to a wide array of downstream tasks.[INTERACTIVE_DEMO]What Makes Curia Different?Unlike existing models that are often trained on narrower and task-specific datasets, Curia was trained on the entire cross-sectional imaging output of the Centre d’Imagerie du Nord (CIN) in Paris, France, over several years. The CIN has been a long-term partner of Raidium, and all imaging data have been collected in accordance with the highest data privacy standards. This massive corpus comprises 150K exams, totaling 130TB of real-world data, including over 200 million CT and MRI slices, from head to toe. This extensive and uniform training on clinical routine images provides Curia with a deep, transferable understanding of complex anatomy and pathology, mitigating biases that can limit generalizability.Unprecedented Performance and Emergent PropertiesWe built a new curated external validation benchmark comprising 19 diverse tasks spanning multiple modalities and diseases. Curia meets or surpasses the performance of both radiologists and recently published foundation models (including Biomed CLIP, BiomedParse, and MedImageInsight). Our evaluations demonstrate several clinically significant emergent properties:Unparalleled Performance: Curia consistently outperforms other foundation models across numerous tasks. Curia-L achieves near-perfect accuracy of 98.39% in organ classification on CT scans, significantly outperforming BiomedCLIP (88.19%) and MedImageInsight (84.96%).Cross-Modality Generalization: Despite being trained without explicit pairing of CT and MRI data, Curia exhibits a remarkable ability to generalize features from one modality to another. For example, Curia-L exhibits a more balanced accuracy decrease (-9.17 percentage points) when evaluated on out-of-distribution MRI data compared to the larger drops seen in MedImageInsight (-35.51 percentage points) and BioMedCLIP (-43.01 percentage points).Few-Shot Learning: Curia demonstrates strong few-shot learning capabilities (the ability to learn to recognize patterns and make predictions with a very small number of training examples), achieving high accuracy with a minimal number of labeled examples. This is particularly advantageous in the medical field, where large, expertly annotated datasets are often resource-intensive to create.Clinical Impact: Curia delivers performance comparable to, or even exceeding, the accuracy of senior resident radiologists on benchmark tasks across various specialties. On average, Curia-L achieves a 89.3% prediction rate, compared to an average 79.1% prediction rate for radiologists.Benchmarking Against State-of-the-Art ModelsWe rigorously compared Curia against leading foundation models in radiology using our newly developed, real-world data benchmark, the first of its kind for foundation models. This benchmark, with its 19 distinct radiological tasks spanning both CT and MRI modalities and covering most anatomical regions, provides a standardized and rigorous method for evaluating a model's general performance. It encompasses a wide spectrum of diseases that radiologists encounter, including disorders related to aging, emergencies, infectious diseases, and oncological conditions.In our benchmark, we compared Curia with state-of-the-art foundation models:MedImageInsight: An open-source visual embedding model by Microsoft, trained on multi-modal medical data from various domains (radiology, histology, pathology, dermatology, ophthalmology), for a total of 3.8M images.BiomedCLIP: A ViT-B model trained with contrastive learning on 15M (image, text) pairs extracted from PubMed.The Power of Curia in Clinical PracticeCuria's capabilities extend beyond just interpreting single images. One of its most significant use cases is co-registration, a process that aligns different medical images to provide a more comprehensive view. Curia consistently outperforms other models in complex registration tasks, including CT-to-CT, MRI-to-MRI, and even the more challenging cross-modality CT-to-MRI alignments. For instance, Curia-L achieved the highest mean Dice Similarity Coefficient (DSC) for CT-to-CT registration (81%) and MRI-to-MRI registration (86%). This ability to align images from different modalities is crucial for tasks like surgical planning and tracking disease progression.In addition to registration, Curia helps predict the survival rate in cancer patients. Going deeper than a simple binary classification of benign or malignant tumors, the model can help predict a patient's survival time using a cox regression model on the model’s features. This capability is a significant advancement, as the model's predictions are more accurate than conventional tumor staging methods.Finally, Curia's proficiency in anatomy classification is a foundational strength. The model achieves near-perfect accuracy (98.40%) in organ classification on CT scans, significantly outperforming BiomedCLIP (88.19%) and MedImageInsight (84.96%). This strong performance extends to MRI data as well, with Curia-L achieving an accuracy of 89.11%. This fundamental understanding of anatomy is critical for a wide range of diagnostic tasks and serves as a building block for more complex applications.To accelerate progress in the field, we are releasing the Curia-B model that shows great performance on all tasks. We also plan to release the 19-task external validation benchmark.Ready to explore Curia? Here’s where to start:Download Curia-B code from HuggingFaceRead our preprint on arXivContact us to access Curia-L model.Looking Ahead: On the Path Towards General Purpose Radiology Models and ProductsWhile Curia represents a significant leap forward, our work continues. Future developments will focus on incorporating rich, multimodal data from electronic health records and textual reports, aiming for an even deeper contextual understanding of relevant medical knowledge and enabling conversational interactions with the model using natural language.Curia provides a robust foundation and a standardized benchmark for future research, paving the way for more powerful, versatile, and data-efficient AI tools that aim to enhance diagnostic accuracy and assist clinical workflows, ultimately improving patient outcomes.Finally, while the Curia model itself is a significant technical achievement, we recognize that its true impact lies in its clinical application. To bridge the gap between research and routine practice, we have developed a novel AI-native, promptable PACS viewer. This interface is designed to seamlessly integrate Curia into established physician workflows, enabling radiologists to interact with the model through visual and textual prompts. By providing a concrete platform for using the model, this viewer lays the groundwork for covering all radiological workflows in the future, making the power of foundation models accessible for radiology practice.For more updates as we continue to push the boundaries of AI in precision radiology:[SUBSCRIBE_BUTTON]Thank you to our co-authors: Jean Du Terrail (.omics), Dr Mariam Moshiri (Department of Radiology and Radiological Science, Medical University of South Carolina), Dr Laurent Dercle (Department of Radiology, Columbia University Irving Medical Center), Dr Tom Boeken (Department of Vascular and Oncological Interventional Radiology, Hôpital Européen Georges Pompidou AP-HP, Université Paris-Cité, HEKA, INRIA, INSERM PARCC U 970), Dr Jules Gregory (HEKA, INRIA, INSERM PARCC U 970), Pr Maxime Ronot (HEKA, INRIA, INSERM PARCC U 970), Dr François Legou (Centre Cardiologique du Nord), Dr Pascal Roux (Centre Cardiologique du Nord), Pr Marc Sapoval (Department of Vascular and Oncological Interventional Radiology, Hôpital Européen Georges Pompidou, AP-HP). Also, thank you to our partners CIN, Jean Zay (IDRIS + GENCI), and Leonardo (CINECA, EuroHPC)
Foundation models: The key to solve radiology through AI?
November 16, 2022
In 2016, Geoffrey Hinton, one of the 3 founding fathers of deep learning, predicted in the 5 coming years the end of the radiologist, who was like the coyote who did not yet know that the ground was collapsing under him with the rising of AI.In 2022, radiologists are still there. Although the prediction is wrong in its temporality, a paradigm shift is taking place in the world of medicine, even more striking in radiology. Some data can testify to this phenomenon : the number of AI solutions validated by the FDA, largely dominated by radiology.But…This huge number is misleading. It does not say anything about the problem linked to the adoption of AI by doctors, who consider these products to be of little or no use, and end up disengaging from it, like the useless applications that clutter our smartphones. Some even speak of an “adoption crisis” of AI in radiology.However, the needs are there: there are always more examinations in an ever more technical medicine, and radiologists are still too rare, and take a long time to train (around 10 years of study). And this increasing demand have impact on radiologist lives : 49% of them show sign of burnout in US. We need more intelligently designed tools to tackle this growing demand. Because radiology saves lives: for example, early diagnosis of lung cancer with CT scan have huge impact on outcome of patients at risk (95% of 5-year survival in stage Ia), while cancer diagnosed too late, as is currently the case for 75% of patients, have a much worse prognosis (16% 5-year survival without screening program).If radiology is among the disciplines to have seen the emergence of the first generation of deep learning based softwares, it will probably be the among the first medical domain that will see the next appear.AI has seen its paradigm change in recent years. Larger and larger models have emerged, showing impressive results in Natural Language Processing (NLP) such as GPT-3, or even more spectacular ones, such as DALL-E or stable diffusion, capable of very realistic image generation from a single prompt.The rise of Foundation models gives us a signal about this paradigm shift.Biological intuition behind Foundation models Let’s take the example of a child: his brain learns a lot of things in an unsupervised way, i.e. without his parents. Thus, a representation of the world is created by probabilistic learning, via observation and interaction with its environment. Parents do not explain the physics laws, such as gravity, to a one-year-old child, who nevertheless builds a first model based on his perceptions: by observing the phenomenon (astonishment at the fall of an object, etc.) or interaction with its environment (learning to walk, for example). It will be the same for language with the emergence of the first words, which are not necessarily dictated to the child, or in the development of the visual area in the brain, which allows autonomous recognition of shapes, contrasts, faces… This emerging phenomenon of autonomous learning, however, does not exclude the role of education and supervision. However, the supervision cost is lower when it is based on prerequisites. Thus, a child will learn more words faster with the help of parents or teachers. The same is true for machines, the first generations of which were based on this principle, with the concepts of transfer learning, consisting of using a pre-trained network for a new task. This principle turns out to be even more efficient with the use of foundation models.A new generation of AI with Foundation modelsEven if this idea of autonomous learning seems simple and intuitive (because this is the way we’ve all learned!), this is not how current Machine Learning models are designed: The Machine Learning models that power most of the current AI applications rely on Supervised Learning. These models are designed to solve only one task and are thus models of little to intermediate size. For example, a Resnet-50 has about 25 million parameters. This comes in parallel with the limited size of supervised learning datasets; For example, there are 1.3 million images in the ImageNet ILSVRC dataset.While these numbers may seem a lot, the numbers encountered in the Foundation models paradigm are orders of magnitude higher.Indeed, Foundation Models are trained on a very large amount of unlabeled data, which is way more available than labelled ones. For example, the Florence Foundation model is trained on a corpus of 900M pairs of text and images.These Foundation Models are able to surpass supervised models on supervised tasks: For example, the COCA Foundation model is the current best-performing algorithm on the ImageNet classification task. However, the Foundation Models are not only better than supervised models on their tasks, they also open the way to many tasks that were not reachable.For example, the PaLM model developed by Google can explain jokes, summarise texts, translate between programming languages, and many others tasks: Even if Foundation models originated in the language realm, they are evolving fast to use multiple modalities at the same time. For instance, DALL-E relies on the CLIP Foundation model, and the BEiT-3 algorithm had better performance in multimodal tasks involving text and images.What can be done with the use of Foundation models?Foundation models already exist with specific use cases outside of medicine. For example, we already use at Raidium tools based on this technology: Github Copilot, based on GPT-3 allows you to code faster, by using a “prompt” which acts like a semi-automatic order for writing lines of code, saving precious time.This design inspires us. Do not automate a job, but make it more efficient by creating tools to serve those who use it. A desirable disruption in a way.Our objective at Raidium is to transfer these advanced technologies to the world of medical imaging, for research as well as for clinical practice. For that, we’ll need to build new tools in the context of a medical environment full of legacy software.For this, we want to aim for a world premiere: build a first Foundation model for radiology, in order to build a visual assistant, a “GitHub Copilot” of radiology. In a context of growing needs of precision medicine, which already overcomes the supply of radiologists, such a Foundation Model will open a brand new world of radiological practice, by a smarter development of AI-based imaging biomarkers, with large models that both embed visual and medical knowledge, making the development of AI more agile and scalable than existing solutions. At Raidium, we want to focus on medical use cases where radiology can have a huge impact on outcomes, such as cancer detection, metabolic or cardiovascular diseases.We think the positive impact of this technology is big for Healthcare. Doctors will be more efficient in their work, clinical research will be accelerated, and in the end, everyone wins: as patients, we will all benefit from a more efficient medicine.This challenge will not happen by itself, because the mission is ambitious. If you want to participate, stay in touch![SUBSCRIBE_BUTTON]